Extracting Websites as Markdown data
Convert any webpage into clean Markdown — ideal for AI analysis.
Simplescraper enables you to easily extract and save a webpage, or an entire website's text content, in Markdown format. Markdown retains the page formatting and is a preferred format when analyzing web date using AI models such as OpenAI's ChatGPT and Anthropic's Claude.
There are a number of ways to save website data as Markdown format with Simplescraper:
Via Crawl entire websites
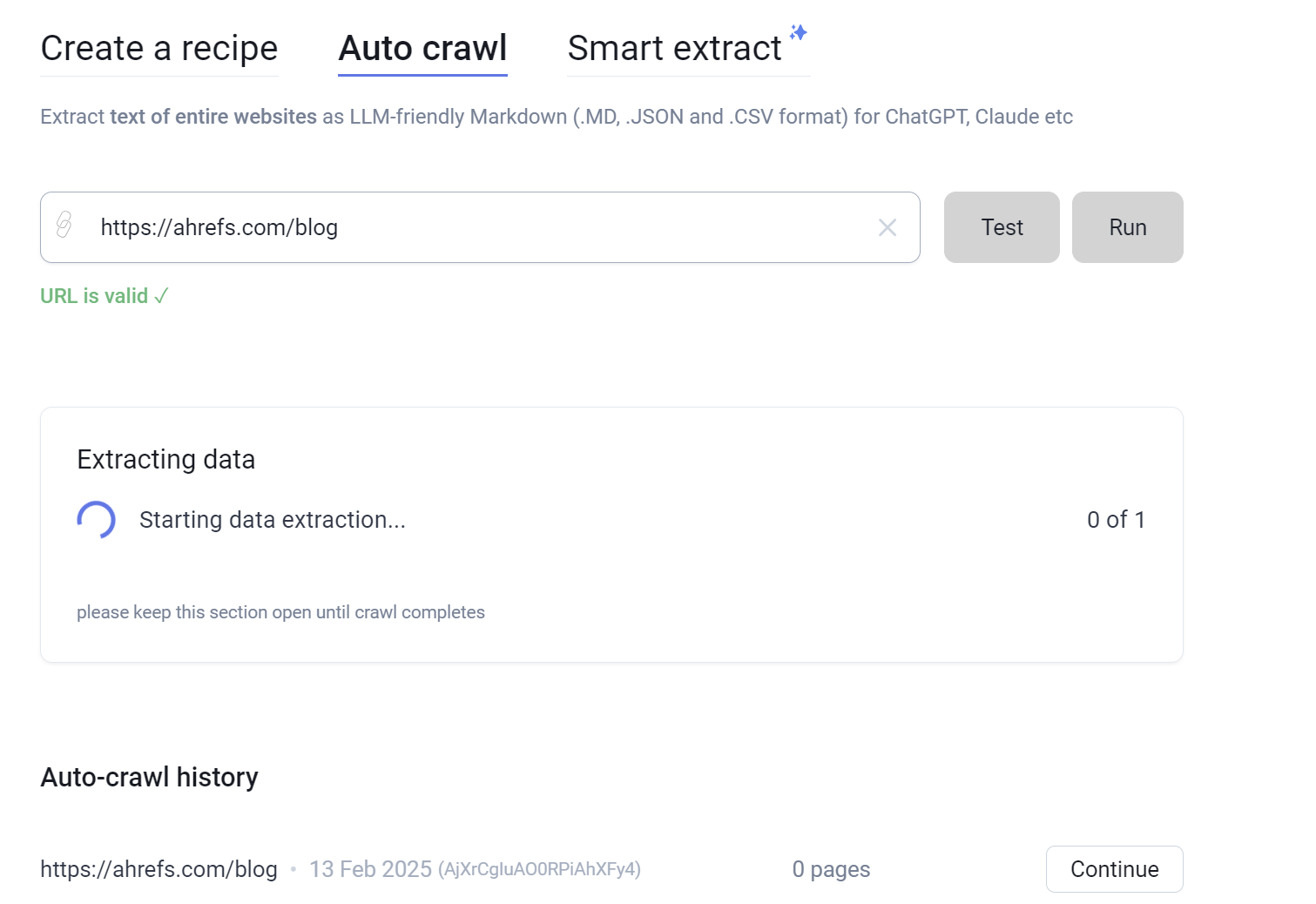
- Visit the Simplescraper dashboard and click 'Get new data' in the sidebar, then select 'Crawl entire websites'
- Enter the URL of the website you wish to save as Markdown
- Under the crawl options, choose the maximum number of pages to scrape and any URL patterns to restrict the crawl to
- Click the 'Test' button to run a quick crawl on two pages. After a few seconds, results will appear - check them to ensure the data looks correct before proceeding
- Click 'Run' and Simplescraper will navigate through the website, saving a Markdown version of each page
- When the crawl is completed, download options for Markdown, JSON, and CSV will appear
Continuing a crawl
If you originally set a limit on the number of pages or ran out of credits and want to scrape more:
- In the crawl history at the bottom of 'Crawl entire websites', click the 'Continue' button next to one of your previous crawls
- The website's URL will load. Increase the page limit as needed (for example, if you scraped 1000 pages before and now want to scrape 3000, enter 3000)
- Click 'Run' and Simplescraper will continue to crawl the website, scraping only those pages that were not previously scraped
- When the task is completed, updated Markdown, JSON and CSV download options will appear
Via a list of URLs
If you already know exactly which pages you want, there's no need to crawl:
- Open 'Get new data' in the sidebar, then select 'Scrape webpages'
- Choose 'Multiple URLs' and paste one URL per line (a single page works the same way via 'Single URL')
- Under 'Data required', select 'Markdown'
- Click 'Get data' and Simplescraper will save each page as clean Markdown, with the same Markdown, JSON, and CSV download options when the run completes
Via a scrape recipe
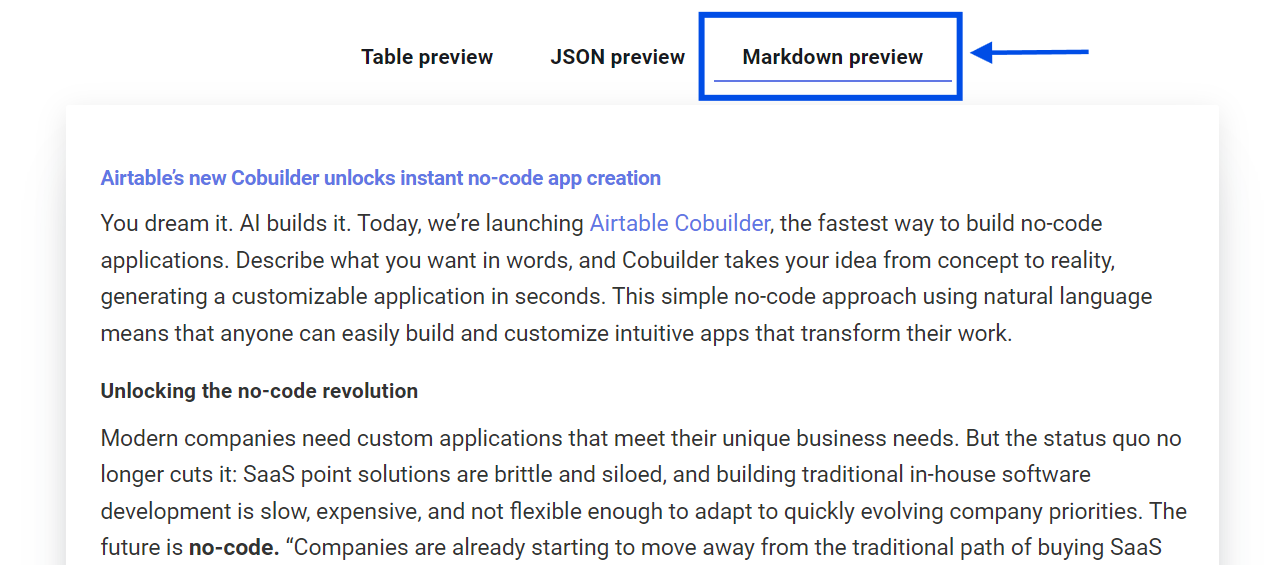
When saving a scrape recipe (this guide covers saving recipes), click the Advanced options section and toggle the 'Extract Markdown' button to the on position
Run your recipe and the Markdown will appear in its own column and a 'download Markdown' button will be available
Note that if the Markdown is very large (over 10MB), the file will be downloaded as a zip

Via the API
When calling the Simplescraper API, include
extractMarkdown: truein the body of the request- js
const apikey = 'ap1k3y'; const requestBody = { extractMarkdown: true, }; const response = fetch(`https://api.simplescraper.io/v1/recipes/${recipeId}/run`, { method: 'POST', headers: { 'Authorization': `Bearer ${apikey}`, 'Content-Type': 'application/json' }, body: JSON.stringify(requestBody) })
Please read the full API guide for more details on data extraction via the API: https://simplescraper.io/docs/api-guide
Extracting URLs
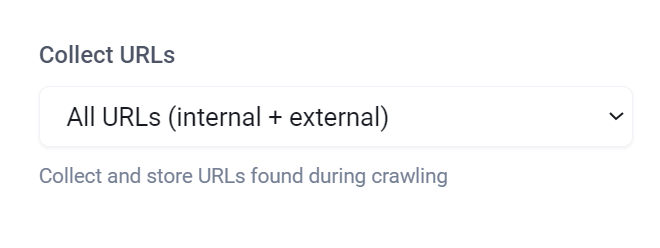
When crawling entire websites, you can also extract all URLs discovered during the crawling process. In the crawl options, under 'Collect URLs', choose from the following:
- Don't collect URLs: No URLs will be extracted
- All URLs (internal + external): Extract every URL found on the crawled pages
- Internal URLs only: Extract URLs from the same domain only
- External URLs only: Extract URLs from different domains only
The extracted URLs will be available as a CSV download option alongside the Markdown content when the crawl completes.